
It's been one year since I joined Genestack: I can safely say that it's been the quickest year of my life! Last February I was welcomed by a brilliant and ambitious team who had managed to build a competitive cloud-based Bioinformatics platform in little more than one year. Thinking about how much the Genestack Core team achieved with such limited time and resources, you do wonder whether some investors didn't bet on the wrong horse! But that was just the beginning: the new Genestack Bioinformatics team worked really hard in the last 12 months to build upon such solid foundations. Genestack's Genomics Operating System has been designed with two main users in mind: researchers/clinicians and third-party developers. I immediately realized how challenging it was going to be to accommodate such a diverse audience on the same platform. Some users want quick and reliable results; some others might want to tune the details of the analysis, and someone else might even want to directly implement her/his favourite script. It sounds a little scary, doesn't it“ It should: when you build a universal platform for bioinformatics there are no easy solutions. You might ask, "how do you do it“" Well, the real question is: "how DID you do it“". Thanks for asking! We designed the architecture of our first-party Genestack Bioinformatics apps around three core principles: completeness, modularity and accessibility.
 1. Completeness
1. Completeness Genestack apps follow your biological data through all phases of its life: production (Preprocessing), analysis (Analyse) and interpretation (Explore). Genestack is not meant to be a basic platform for "running pipelines online": when you analyse your data on Genestack the end point is biological discovery. Apps like the Genestack Genome Browser go even beyond, thanks to rich features for formula tracks and visual analytics.
 2. Modularity
2. Modularity First-party Genestack apps are modular. It's easy to assemble a Data Flow based on widely popular tools, and third-party developers of Genestack apps can choose to create focused tools or to consolidate entire pipelines into "magic box" solutions. With this approach, biologists and clinicians with a less strong bioinformatics background have a clearer understanding of how their data is analysed at each step, and third-party Genestack developers have an easier time introducing their original solutions for even just one step of a pipeline. It's a win-win situation for everybody.
 3. Usefulness Genestack bioinformatic apps are designed around a core task (e.g. "Spliced Mapping") and offer selected, easy to understand options (e.g. "Include non-variant positions in the output" Y/N). We are not interested in flooding users with hundreds of random tools: Genestack is a data-centric platform, and what matters is your data and the questions you want to ask. Moreover, many bioinformatic tools ask users to assimilate dozens of parameters, at times going into the three digits. In some cases such complexity is fully justified, and fine-tuning can be relevant for a specific analysis, but not all arguments are coded equal. When designing the interface of our apps we chose to focus on fewer options which are of general interest for the most common NGS pipelines. This greatly helps new users to focus on getting the job done without having to assimilate multiple manuals. At the same time, Genestack SDKs allow third-party developers and bioinformaticians to create more complex apps for the same task, implementing new options or maybe even a different algorithm.
3. Usefulness Genestack bioinformatic apps are designed around a core task (e.g. "Spliced Mapping") and offer selected, easy to understand options (e.g. "Include non-variant positions in the output" Y/N). We are not interested in flooding users with hundreds of random tools: Genestack is a data-centric platform, and what matters is your data and the questions you want to ask. Moreover, many bioinformatic tools ask users to assimilate dozens of parameters, at times going into the three digits. In some cases such complexity is fully justified, and fine-tuning can be relevant for a specific analysis, but not all arguments are coded equal. When designing the interface of our apps we chose to focus on fewer options which are of general interest for the most common NGS pipelines. This greatly helps new users to focus on getting the job done without having to assimilate multiple manuals. At the same time, Genestack SDKs allow third-party developers and bioinformaticians to create more complex apps for the same task, implementing new options or maybe even a different algorithm.  Roll call
Roll call With these ideas in mind, in the last year Genestack introduced dozens of new free apps which allow our users to perform analysis of Next-Generation Sequencing data, including Whole Exome Sequencing, RNA-seq, single-cell RNA-seq, BS-seq and more. It would take several blog posts to tell you about each one, but we can give you a glimpse of what is currently available:
- Preprocess
- Concatenate Variants
- Filter Reads by Quality Scores
- Filter Duplicated Reads
- Mark Duplicated Reads
- Merge Reads
- Merge Variants
- Subsample Reads
- Trim Adaptors and Contaminants
- Trim Low Quality Bases
- Trim to Fixed Length
- Analyse
- Single-cell RNA-seq Analysis
- Variant Calling
- Variant Annotation
- Quantify Raw Coverage in Genes
- Quantify FPKM Coverage in Isoforms
- Test Differential Gene Expression
- Test Differential Isoform Expression
- Unspliced Mapping
- Spliced Mapping
- Bisulfite Sequencing Mapping (RRBS)
- Bisulfite Sequencing Mapping (WGBS)
- Methylation Ratio Analysis
- Explore
- Genome Browser
- Single-cell RNA-seq Visualiser
- Raw Reads QC Report
- Mapped Reads QC Report
- Multiple QC Report
- Expression Navigator
- GO Enrichment Analysis
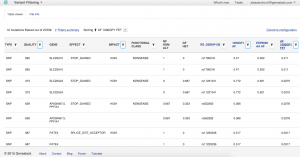
- Variant Filtering
- Sequencing Assay Viewer
- File Provenance
- Metainfo Viewer
 What's next“
What's next“ After the huge success in 2014 of the Genestack apps for Single-cell RNA-seq Analysis, we will soon release updated versions of our apps for gene and isoform expression analysis, adding tools for novel transcript discovery. Most importantly, our current apps for Variant Calling will soon be updated; our newest Genestack pipeline for Genomic Variant Analysis allows you to analyse variants for hundreds of exome samples at once. Last but not least, our Public Data repository keeps growing! We are developing a unified repository of all available sequencing data. The end result is not just a simple list: every published NGS dataset will be loadable on Genestack, allowing you to reproduce your analyses and compare results with published datasets. There is a bright future ahead of Genestack: stay with us, and help us develop the first true universal platform for bioinformatics data analysis!
Get your free Genestack account at https://genestack.com/blog/  It's been one year since I joined Genestack: I can safely say that it's been the quickest year of my life! Last February I was welcomed by a brilliant and ambitious team who had managed to build a competitive cloud-based Bioinformatics platform in little more than one year. Thinking about how much the Genestack Core team achieved with such limited time and resources, you do wonder whether some investors didn't bet on the wrong horse! But that was just the beginning: the new Genestack Bioinformatics team worked really hard in the last 12 months to build upon such solid foundations. Genestack's Genomics Operating System has been designed with two main users in mind: researchers/clinicians and third-party developers. I immediately realized how challenging it was going to be to accommodate such a diverse audience on the same platform. Some users want quick and reliable results; some others might want to tune the details of the analysis, and someone else might even want to directly implement her/his favourite script. It sounds a little scary, doesn't it“ It should: when you build a universal platform for bioinformatics there are no easy solutions. You might ask, "how do you do it“" Well, the real question is: "how DID you do it“". Thanks for asking! We designed the architecture of our first-party Genestack Bioinformatics apps around three core principles: completeness, modularity and accessibility.
It's been one year since I joined Genestack: I can safely say that it's been the quickest year of my life! Last February I was welcomed by a brilliant and ambitious team who had managed to build a competitive cloud-based Bioinformatics platform in little more than one year. Thinking about how much the Genestack Core team achieved with such limited time and resources, you do wonder whether some investors didn't bet on the wrong horse! But that was just the beginning: the new Genestack Bioinformatics team worked really hard in the last 12 months to build upon such solid foundations. Genestack's Genomics Operating System has been designed with two main users in mind: researchers/clinicians and third-party developers. I immediately realized how challenging it was going to be to accommodate such a diverse audience on the same platform. Some users want quick and reliable results; some others might want to tune the details of the analysis, and someone else might even want to directly implement her/his favourite script. It sounds a little scary, doesn't it“ It should: when you build a universal platform for bioinformatics there are no easy solutions. You might ask, "how do you do it“" Well, the real question is: "how DID you do it“". Thanks for asking! We designed the architecture of our first-party Genestack Bioinformatics apps around three core principles: completeness, modularity and accessibility.  1. Completeness Genestack apps follow your biological data through all phases of its life: production (Preprocessing), analysis (Analyse) and interpretation (Explore). Genestack is not meant to be a basic platform for "running pipelines online": when you analyse your data on Genestack the end point is biological discovery. Apps like the Genestack Genome Browser go even beyond, thanks to rich features for formula tracks and visual analytics.
1. Completeness Genestack apps follow your biological data through all phases of its life: production (Preprocessing), analysis (Analyse) and interpretation (Explore). Genestack is not meant to be a basic platform for "running pipelines online": when you analyse your data on Genestack the end point is biological discovery. Apps like the Genestack Genome Browser go even beyond, thanks to rich features for formula tracks and visual analytics.  2. Modularity First-party Genestack apps are modular. It's easy to assemble a Data Flow based on widely popular tools, and third-party developers of Genestack apps can choose to create focused tools or to consolidate entire pipelines into "magic box" solutions. With this approach, biologists and clinicians with a less strong bioinformatics background have a clearer understanding of how their data is analysed at each step, and third-party Genestack developers have an easier time introducing their original solutions for even just one step of a pipeline. It's a win-win situation for everybody.
2. Modularity First-party Genestack apps are modular. It's easy to assemble a Data Flow based on widely popular tools, and third-party developers of Genestack apps can choose to create focused tools or to consolidate entire pipelines into "magic box" solutions. With this approach, biologists and clinicians with a less strong bioinformatics background have a clearer understanding of how their data is analysed at each step, and third-party Genestack developers have an easier time introducing their original solutions for even just one step of a pipeline. It's a win-win situation for everybody.  3. Usefulness Genestack bioinformatic apps are designed around a core task (e.g. "Spliced Mapping") and offer selected, easy to understand options (e.g. "Include non-variant positions in the output" Y/N). We are not interested in flooding users with hundreds of random tools: Genestack is a data-centric platform, and what matters is your data and the questions you want to ask. Moreover, many bioinformatic tools ask users to assimilate dozens of parameters, at times going into the three digits. In some cases such complexity is fully justified, and fine-tuning can be relevant for a specific analysis, but not all arguments are coded equal. When designing the interface of our apps we chose to focus on fewer options which are of general interest for the most common NGS pipelines. This greatly helps new users to focus on getting the job done without having to assimilate multiple manuals. At the same time, Genestack SDKs allow third-party developers and bioinformaticians to create more complex apps for the same task, implementing new options or maybe even a different algorithm.
3. Usefulness Genestack bioinformatic apps are designed around a core task (e.g. "Spliced Mapping") and offer selected, easy to understand options (e.g. "Include non-variant positions in the output" Y/N). We are not interested in flooding users with hundreds of random tools: Genestack is a data-centric platform, and what matters is your data and the questions you want to ask. Moreover, many bioinformatic tools ask users to assimilate dozens of parameters, at times going into the three digits. In some cases such complexity is fully justified, and fine-tuning can be relevant for a specific analysis, but not all arguments are coded equal. When designing the interface of our apps we chose to focus on fewer options which are of general interest for the most common NGS pipelines. This greatly helps new users to focus on getting the job done without having to assimilate multiple manuals. At the same time, Genestack SDKs allow third-party developers and bioinformaticians to create more complex apps for the same task, implementing new options or maybe even a different algorithm.  Roll call With these ideas in mind, in the last year Genestack introduced dozens of new free apps which allow our users to perform analysis of Next-Generation Sequencing data, including Whole Exome Sequencing, RNA-seq, single-cell RNA-seq, BS-seq and more. It would take several blog posts to tell you about each one, but we can give you a glimpse of what is currently available:
Roll call With these ideas in mind, in the last year Genestack introduced dozens of new free apps which allow our users to perform analysis of Next-Generation Sequencing data, including Whole Exome Sequencing, RNA-seq, single-cell RNA-seq, BS-seq and more. It would take several blog posts to tell you about each one, but we can give you a glimpse of what is currently available: 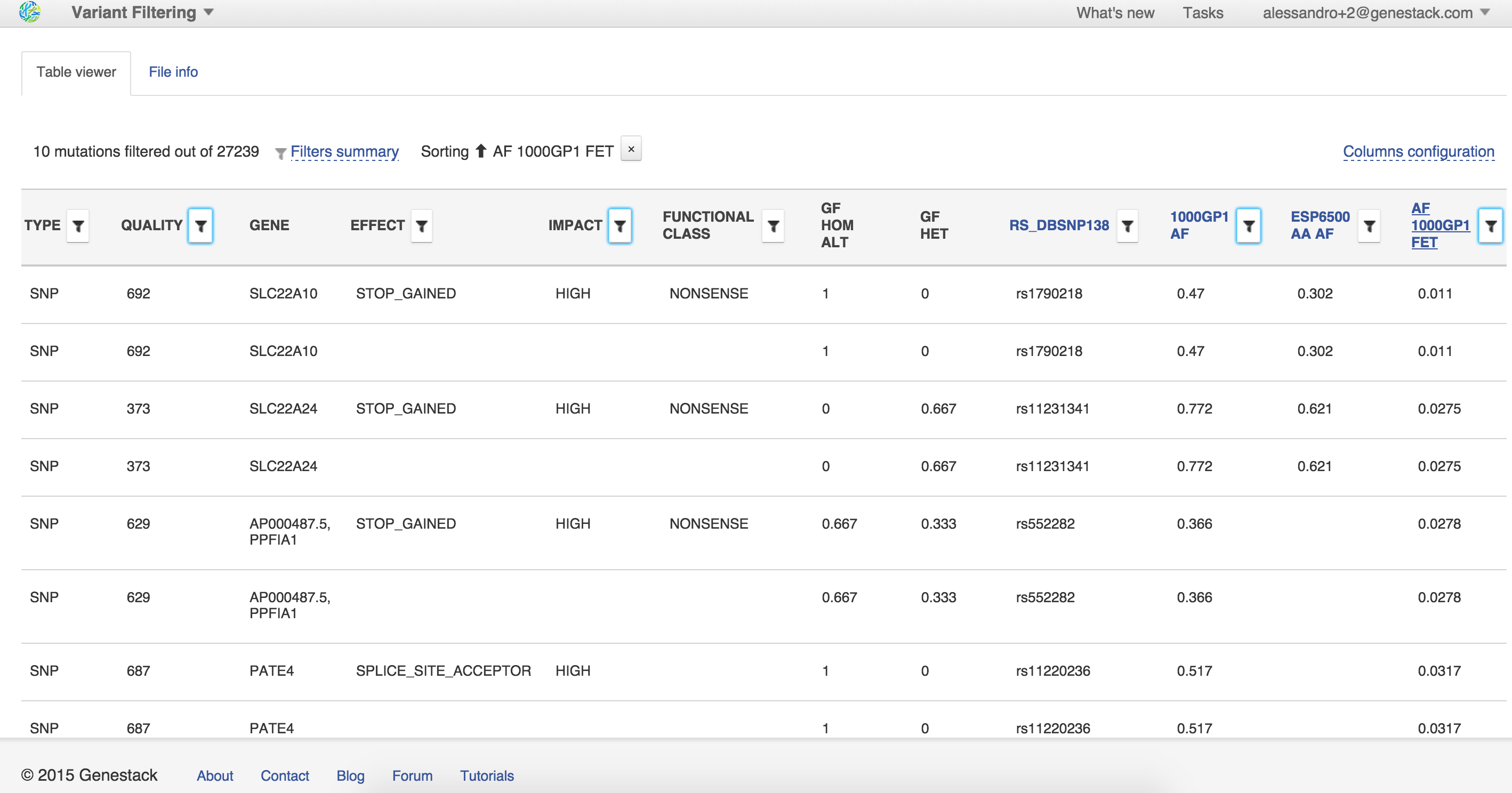 What's next“ After the huge success in 2014 of the Genestack apps for Single-cell RNA-seq Analysis, we will soon release updated versions of our apps for gene and isoform expression analysis, adding tools for novel transcript discovery. Most importantly, our current apps for Variant Calling will soon be updated; our newest Genestack pipeline for Genomic Variant Analysis allows you to analyse variants for hundreds of exome samples at once. Last but not least, our Public Data repository keeps growing! We are developing a unified repository of all available sequencing data. The end result is not just a simple list: every published NGS dataset will be loadable on Genestack, allowing you to reproduce your analyses and compare results with published datasets. There is a bright future ahead of Genestack: stay with us, and help us develop the first true universal platform for bioinformatics data analysis! Get your free Genestack account at https://genestack.com/blog/
What's next“ After the huge success in 2014 of the Genestack apps for Single-cell RNA-seq Analysis, we will soon release updated versions of our apps for gene and isoform expression analysis, adding tools for novel transcript discovery. Most importantly, our current apps for Variant Calling will soon be updated; our newest Genestack pipeline for Genomic Variant Analysis allows you to analyse variants for hundreds of exome samples at once. Last but not least, our Public Data repository keeps growing! We are developing a unified repository of all available sequencing data. The end result is not just a simple list: every published NGS dataset will be loadable on Genestack, allowing you to reproduce your analyses and compare results with published datasets. There is a bright future ahead of Genestack: stay with us, and help us develop the first true universal platform for bioinformatics data analysis! Get your free Genestack account at https://genestack.com/blog/