
The six most common pitfalls and how to avoid them.
Life Science Data has now become a key success ingredient in pharmaceutical R&D, from target identification, to patient selection in clinical trials. However, organizations spend far too much time harmonizing and integrating data, rather than applying them and extracting valuable insight from them. This is because of data stuck in silos, incompatible data and metadata, and scalability issues.
Benefits of a more integrated and scalable data landscape
Organizations with a data strategy in place are now striving for a more scalable and FAIR data landscape. This is understandable, because the benefit is transformative:
- It leads to data democratization, which increases researcher efficiency, amounting to at least $4M per year per 100 researchers
- It leads to higher data utilization, which causes fewer redundant experiments, amounting to at least $2M per year per 100 experiments
- It leads to better target, dosing strategy, and selection biomarkers, which lowers trial cost and improves the likelihood of success, easily amounting to $300M per drug
Not only this brings big savings and efficiency improvements at an organizational level, but it also increases the productivity of single scientists: for example, with a more integrated and scalable data landscape you’ll be able to build a powerful app like a single-cell atlas in just 1 day, by 1 data scientist, instead of having to wait for a year and investing a million dollars. This is only possible if you have solid data integration capabilities in place.
Related:
> Genestack signs multi-year agreement with AstraZeneca to implement Genestack ODM
Beware of the six most common pitfalls
Despite data integration being hugely important for R&D organizations, it is very hard to get it right. At Genestack we work on Life Science Data management and integration projects with top pharma, agriscience, and consumer goods companies. We have a deep understanding and inside knowledge of the challenges associated with it, and have seen data initiatives succeed and fail.
There are six most common hurdles that organizations must overcome when building a scalable Life Science Data landscape, three of them cultural, three of them technical. Let’s take a quick look at them.

#1 — Focus on analysis vs integration (cultural)
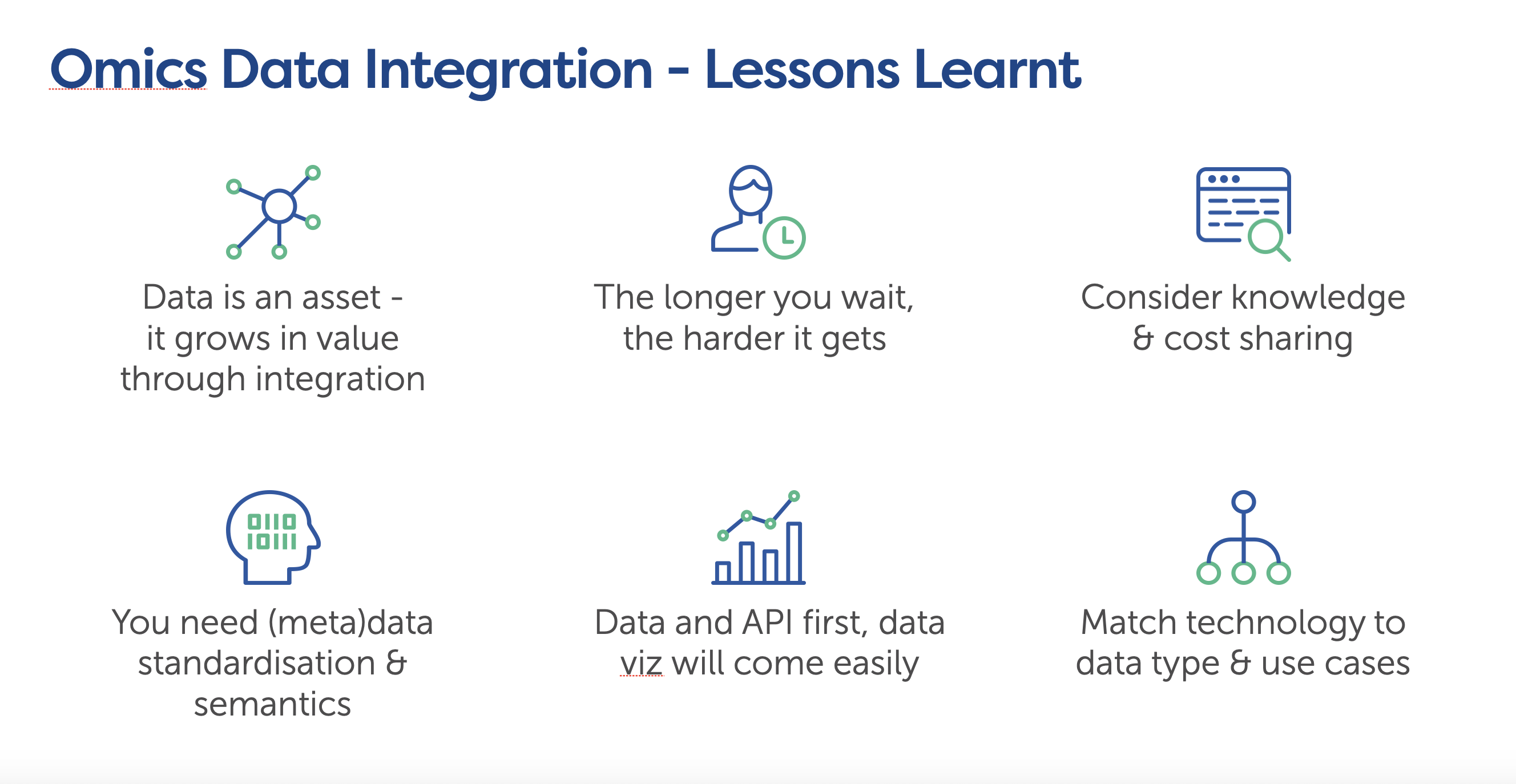
The first pitfall is that organizations tend to have a short-term focus on data analysis, rather than a long-term focus on data integration. What they don’t realize is that data is an asset. Data grows in value through integration.
Some classes of insights, like target identification and patient selection, are only possible when you have a broad and well-annotated dataset. And this is just the tip of the iceberg, high data quality and solid data integration capabilities are an integral part of the promises of precision medicine and machine learning / artificial intelligence in the biopharma sector and beyond.
#2 — Lack of urgency (cultural)
The second pitfall is the lack of urgency. Unfortunately, as with many things in life, the longer you wait to implement a sound and future-proof data strategy, the harder it gets. It’s well known that data preparation is the most time-consuming and least enjoyable part of data science and therefore you want to have data harmonization and integration as close to data acquisition as possible. If your organization is under a low sense of urgency to build an integrated Life Science Data environment, you may want to start asking your organization some questions.
#3 — A perception that the problem is easy enough to solve on your own, in-house (cultural)
The third pitfall is the DIY mentality. We have seen large organizations going down this route but eventually give up, after wasting a lot of money and effort. It’s unsustainable, expensive, and even worse, you might end up creating another data silo, which is one of the very problems you were trying to solve! This is precisely the frustration shared by one of our pharma clients recently.
Related:
> 5 Reasons why building your own software solution is not a good idea
#4 — Over-reliance on Data Lake (technical)
Data lakes implementations tend to lack data standardization, data lineage, and metadata: this won’t help data integration.
What you need is to:
- Organize and structure data into Single Point of Truths
- Have an integration layer to model relationships between data types
- Have metadata management, to ensure minimum information is captured, using ontologies and controlled vocabularies
#5 — Fixating too much on data visualization (technical)
We have seen this countless times. What you’ll find is that data visualization apps tend to be limited in data and functionality. You will end up having to track data across multiple apps, which leads to fragmentation of your data landscape.
A more beneficial and sustainable approach is to have a Single Point of Truth for your Life Science Data, and serve it to different apps via APIs. If you invest into a centralized and reusable data and search capability, meaningful data visualization will come naturally with that.
#6 — Over-dependence on general-purpose technology (technical)
And the last pitfall is over-dependence on a single “one-stop-shop” technology. General-purpose, big data technology, like Spark, may not be the best choice for all the data types and use cases. For example, we manage to get far superior performance for genomics filtering and association analysis, on a single machine, compared to spinning up a big Spark cluster. The bottom line is that to ensure scalability, you want to match different technologies to data types and use cases.
Lessons learnt
In summary, the take home messages for your organization are two:
- It is essential to understand the value, urgency, and difficulty of Life Science Data integration
- You want to ensure good data standardization and semantics, invest in common data and API framework, and match different technologies to data types and use cases.
How we can help you with your Life Science Data landscape
We can help organizations like yours build a more integrated and scalable Life Science Data landscape - we work with both small and some of the largest organisations, including Roche, AstraZeneca, Unilever, and Corteva. Get in touch today for a free consultation with our experts.
Get in touch >