
The idea of adopting a new platform to better catalogue and reuse your data can be intimidating and even scary. For this reason, many companies stick with their existing solution, which makes them less productive as life sciences data grow rapidly in volume and complexity. Here, we will give you the key steps to make the adoption journey smooth and how Genestack can help.
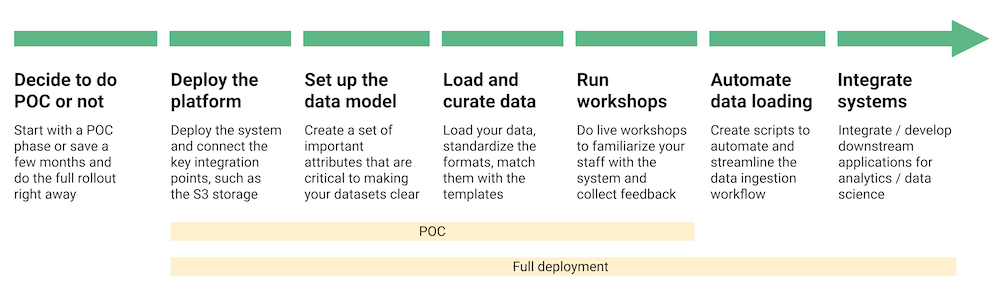
Step 1: Decide to do a POC or not
After running a demo session and concluding that a platform is a good fit for your needs, a good partner should help you see value quickly with minimal investment. Here at Genestack, for example, you can start with a POC phase that focuses on a single department or data type with an initially limited number of users. To do this, you'll need to follow steps 2 through 5 below on a smaller scale. You can also save a few months and start the full rollout right away. In this case, it will be helpful if you follow all the steps below.
Step 2: Deploy the platform
The very first step is to deploy the system and connect some key integration points, such as the cloud storage and scientific ontologies. At Genestack, we have a fast and flexible deployment process that supports on-prem, VPC, or a SaaS model. Depending on which systems you connect, this can take a few days or weeks.
Step 3: Set up the data model
The second step is to decide on a data/metadata model - a set of important attributes that are critical to making your datasets easily discoverable and reusable by others. The template will also help you curate your data in the most efficient way without changing values one by one. At Genestack we can help you create your minimum attributes for study, sample, and omics data types, and connect standard ontologies such as NCBI taxonomy terms, disease ontologies, and many others.
Step 4: Load and curate the data
Now you can start populating the system with your data and harmonising it against the data/metadata model. This step can be complicated and time-consuming, especially if your existing data is scattered across systems. That's why at Genestack this part is usually handled by our professional services team. We load your data from various systems, standardize the formats, match them with the templates we created in the previous step, and find ways to automate the process in the future.
Step 5: Run workshops and surveys
Once the system is up and running, the next step is a series of workshops with different departments of your company to demonstrate the values of the solution. Participants in our recent workshops report that their workflows become two times easier with the Genestack platform compared to their previous solutions.

Step 6. Automate data loading
The more data you have integrated, the more value you can provide to your researchers. Experimental data scattered across spreadsheets form or systems is not actionable. But changing the old habits of your researchers is no easy task. That's why it's so important to work with a vendor who can help with the transition. Here at Genestack we can streamline the data ingestion process by creating scripts to automate the process of collecting and integrating data from common data sources, such as ELNs, pipelines, and other data warehouses.
Step 7. Integrate the downstream applications
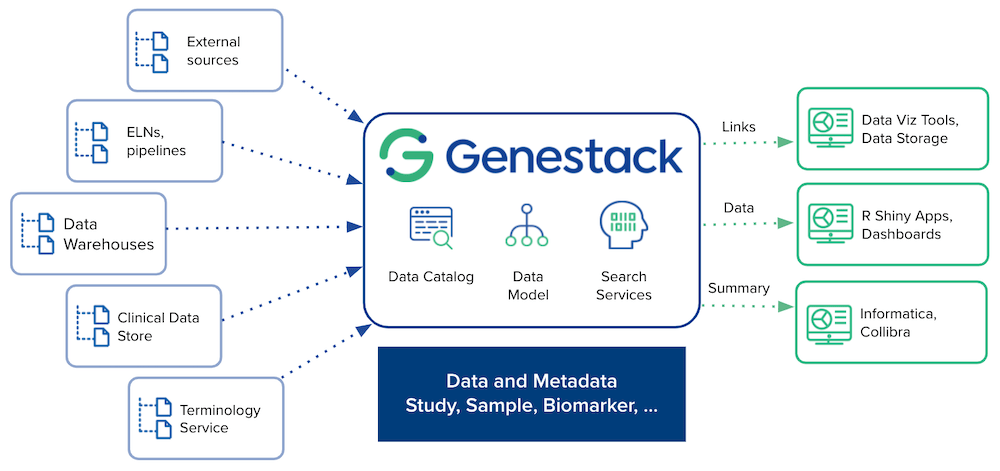
The final step is to connect the new platform to downstream applications that you use to process your data. The Genestack platform can become the SPoT - single point of truth - for all your life sciences data, connecting all your existing solutions. It indexes your data and sends it to different downstream applications. Links to data visualization tools or data stores can be stored as links in the metadata. Data snippets can be sent to R Shiny applications and dashboards, and summaries can be stored in Informatica and Collibra. All of this is possible thanks to a set of APIs that allow you to integrate with any solution.
And all this starts by deciding to try a better management tool for your data.