
What is Federated Learning?
As healthcare providers become more digital and smartphones use your data all the time, many people are concerned about protecting it. But more data means better decisions, especially when developing AI and machine learning models. So is there a way to use sensitive data without any risk? It turns out there is.
Federated learning allows multiple clients to build a standard, powerful machine learning model without sharing data. It means you no longer have to worry about privacy and access rights while still having high predictive accuracy. Instead of learning from data, it learns from other machine learning models created locally by federating them with specific algorithms.
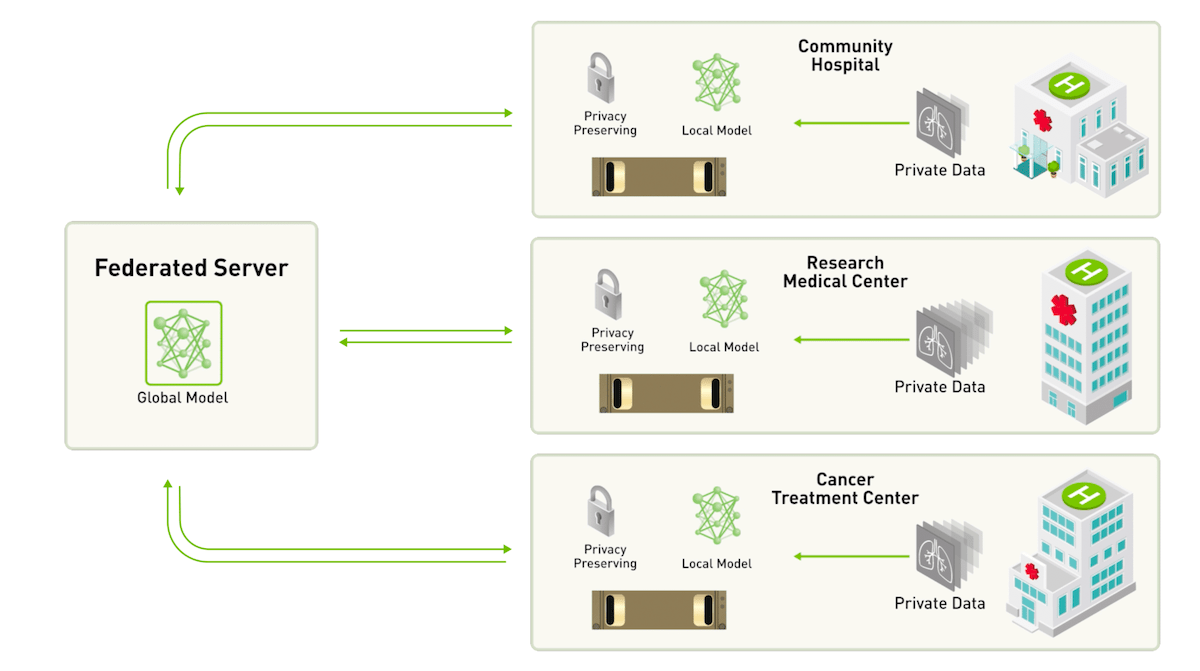
The server sends empty, non-trained models to clients (hospitals). Then each client trains the model on their data and sends it back to the server. (Source)
Where is it used?
Google first introduced Federated Learning in 2016. It was an important milestone in protecting data and creating better recommendations for users, as many Google products for mobile devices are based on machine learning technologies. For example, Google Assistant refines models to recognise "Hey Google" based on voice recordings stored on users' devices.
Quote: Federated learning is a privacy-enhancing technology that we use to improve models on the device without sending users' raw data to Google servers. Source https://support.google.com/assistant/answer/10176224?hl=en
Another area where federated learning can have a significant impact is in healthcare. It has already been proven that a good AI model can save lives by predicting illness. But data from a single hospital or laboratory can never create a good enough model for many. Therefore more attention is being paid to federated learning these days. Just recently, Sanofi invested $180 million in a company using federated learning to advance its oncology pipeline.
How do we do it?
As a provider of data management solutions, it is essential for us that clients can use our service to empower machine learning. To prove the system is capable, we developed an ML model for data distributed across different devices without compromising privacy or losing accuracy. To do this, we used data from the UK Biobank. This system contains information about lifestyle, medical history, biological samples and diagnoses from almost half a million participants from the UK. We used the data from blood samples to predict diabetes, and our main goal was to achieve the same accuracy as with the classical machine learning approach. We used Python with Scikit-Learn to build a model for each client and the FedAvg method from a Flower framework to federate it and achieved remarkable results: The accuracy of a federated model was very close to that of a classic ML model. You can see the ROC AUC curves of both models compared below.
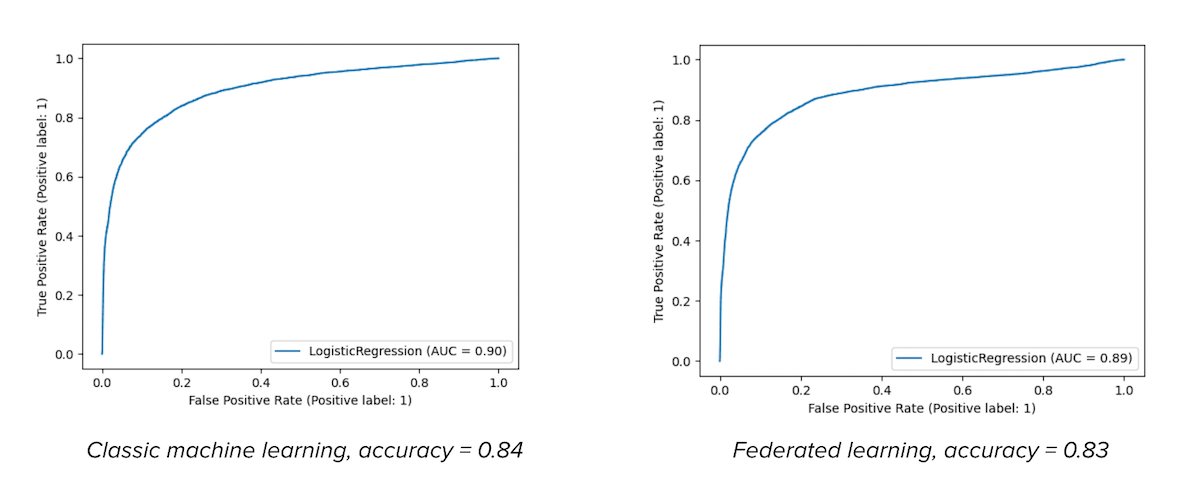
A classic (non-federated) machine learning model is on the right side. On the left side is a model derived using federated learning on two clients. The fact that both figures look almost the same proves that federated ML can be as good as the classical one (Source).
The main finding of our experiment was that federated learning could perform as well as classical ML. But the surprising part is how easy it was to build a federated model. It took us only three days because we used our platform to store and organise the data. It is common knowledge that up to 80% of data scientists each day are searching for data or cleaning it, so having an efficient foundation helps speed up the process and have the prototype ready in three days.
How can you do it?
Setting up a federated learning system may sound intimidating initially, but with the right tools, you will be surprised by how easy it is.
Step 0: Learn more
First, make sure you are familiar with the basic concepts. For example, you can use different algorithms depending on the data type and your goals. You can implement these algorithms' logic yourself, but using existing frameworks is highly recommended first. Then you do not need in-depth mathematical knowledge and have a much easier time.
Step 1. Chose the technology
Choose the right technology stack. Python is highly recommended as a programming language, as it best suits ML. In addition, many frameworks designed for federated learning use this language as a foundation so that you can implement the algorithms yourself from scratch. However, if you are not ready to do it yourself, you should choose a framework with which you are most familiar. There are several options you can start with, but we recommend one of the following:
- Flower is the most user-friendly framework that supports a variety of ML libraries - sklearn, PyTorch, and Tensorflow. If you have already tried ML in any of those libraries, you will find it extremely easy to create your first model. Just run the example code and then adapt it to your data.
- Tensorflow Federated is one of the best solutions if you are already familiar with the concept of tensors. It is the first federated learning solution, with a vast community and many algorithms implemented. A great choice if you are familiar with the concept of tensors and the TensorFlow library.
There are many other frameworks and libraries like SecureBoost, FATE, OpenFL and others. Choose the one you are most comfortable with.
Step 2: Harmonise the data
Make sure you have harmonised your data across devices. It is the most important but also the most time-consuming step. Make sure all your training data has no missing values, has the same structure and uses the same terms. It would help if you took care of all this before you start building federated learning models, as you will not have access to the actual data from the server (model building) side. You will never understand why one client's models perform poorly. Therefore, each client (device) must follow the same data structure rules. After the data is clean, divide it into more extensive training and smaller test data. This step is made more accessible with an appropriately built and managed data management system implemented for each client.
Step 3. Define your ML model type
Define the type of machine learning model you want to use. For example, a linear regression model is a good starting point for predicting continuous values. On the other hand, you can use logistic regression or a support vector machines (SWM) algorithm for a classification task, such as predicting diseases or outcomes. If you are not satisfied with the accuracy of a model, you can also try decision trees, as they perform much better than other algorithms on some tasks.
Step 4. Connect, train and evaluate.
Connect the devices and follow the documentation of your chosen framework to build a federated learning model. Then, use the training data to make the model and evaluate its performance on the test data.
The importance of data management
Just as good Italian pasta is impossible without quality flour, an accurate ML model is impossible without quality data. But having clean data does not happen magically. It can take hard work and time that you do not always have. A perfect opportunity to delegate this task to a professional: a data management platform like Open Data Manager from Genestack. The platform simplifies and automates much of the hard work for you. Just follow the simple steps below.
Clean up your messy data in less than a minute: Replace missing values, change terms, reassign columns - all with a few clicks in the GUI. Made a mistake? No problem, you have a built-in versioning system like GitHub, so you can revert to any state of your dataset without worrying about doing something wrong.
Curate your data using templates and ontologies: The fact that your dataset does not have missing values does not mean you can combine it with other data. For example, imagine a 'gender' column with 'F' and 'M' in one study and 'female' and 'male' in another. It may seem like a small problem, but the federated learning model might not work. So make sure all your datasets have the same columns and use the same controlled vocabulary. The Genestack platform gives you much flexibility: load scientific ontologies to manage the terminology and set templates with mandatory fields to ensure all your data is there before you start building a model.
Finally, when you have all your datasets ready, you can connect them directly to your federated learning scripts using the Genestack APIs. You do not have to manually download and reload the data every time you make a small change.
Want to know more or need a hand? Contact us to learn how we can help you get your data into the best shape for your AI and ML models. www.genestack.com or sales@genestack.com