
Data. A holy grail of any science. We often think that the only thing we want to get once we have data is even more data to enable us to draw a more reliable conclusion regarding how the world works.
Even though data is the only firm asset we have to form and test scientific hypotheses and theories, we are frequently ignorant to its value and don’t care much about it after we’ve finished our specific experiment.
Even though data is the only firm asset we have to form and test scientific hypotheses and theories, we are frequently ignorant to its value and don’t care much about it after we’ve finished our specific experiment.
The most illustrative (and dramatic) analogy of our daily data ignorance is a story of the theory of evolution and natural selection. Charles Darwin could change the world through his careful work with data he (and humanity in general) already had in their possession. Let’s look closer at this first and most iconic data science discovery in Life Sciences.
Collect a new dataset using existing methods of observation. In 1831 Darwin was only 22 when he was invited to a five-year expedition across the globe on HMS Beagle. It started in South America, where he got lots of samples, illustrations, and fossils, bringing the first key ideas of the connection between extinct and existing species. Galapagos brought him turtles’ and finches’ diversity. Then Australia and many more. Darwin returned back to the UK, having a precious observation database in his possession.
Revisit an existing dataset. Back in England, Darwin started to study how people created almost new species of animals and crops and understood that artificial selection was the key to success. He believed that a similar process must happen in nature but could not explain how it acts exactly.
Review publications. The revelation came after reading a book by Thomas Robert Malthus, explaining his “struggle for existence” theory predicting what might happen when the ever-growing European population runs out of resources. Darwin mapped this theory on the dataset analysis he’d done earlier. He realized that “survival of the fittest” is a pretty good explanation of his observations and “a beautiful part of my theory”.
Reconsidered the entire data repository available so far. It was time to look at all the data from a new angle. And not only the data he has collected, but the entire knowledge naturalists had collected for decades. All observations started making sense. Darwin spent about 20 years describing a theory and wasn’t ready to publish it. He needed a nudge, and it came with a letter from Alfred Wallace stating that he had discovered natural selection on his own. Darwin had no choice but to urge publishing his book (and eventually earning all the glory).
Darwin’s theory made him one of the most influential scientists in history. To achieve that, he had to go on a strange journey, do hundreds of experiments, and spend 20 years developing his ideas. He was lucky enough to publish his book, despite having a competitor. But how often have we faced a similar situation of working with the data only to come to a situation when somebody has just published the same findings acting faster?
The world has changed; we have new technologies, scientific advances, and more data than Darwin could ever imagine. But we don’t have the luxury of spending 20 years thinking about a theory and gathering data from scattered sources.
Let’s talk about reducing the time that typically passes from the first glimpse of a scientific idea to the “A-ha! Eureka!” moment.

What are the Roadblocks to Data Enlightenment?
The Life Sciences industry heavily relies on data efficiency to be successful. However, only a few organizations worldwide have removed some of the following blocks.
How many issues from the list below have you spotted in your data-related activities?
Locating the data we know about:
Departments (labs, collaborators, CROs) are often separated by geography, research interest and even budget. Internal data storage and refinement policies are therefore often not established, not consistently followed or even different for each department. This causes data batches to be stored in different places and formats. Typical questions we hear from scientists and bioinformaticians on a daily basis are:
- 1. Where is my data?
- 2. I know another department produces sequencing results; where can I find it?
- 3. What clinical studies have we performed with collaborator X, and on what molecules?
- 4. What are and where are all of the samples for these studies?
- 5. What are and where are all data generated on these samples?
- 6. Find assays with biomarkers measured?
- 7. What are all molecular -omics data generated as part of the study or afterward?
- 8. We know we had done an experiment for a disease X project in the past; we spent six months looking for the dataset across our company.
- 9. Where can I find all the analysis reports for the project?
Locating the data we don't know about. The basis of science is the review of work done so far. It is impossible to plan the subsequent research effectively without full access to all previously generated data/experimental results.
"I need to perform an RnD research. Has any lab in our organization produced such data fully or partially in the past? Do I need to budget and plan a new experiment for the next several months?"
Our lack of knowledge regarding the data we own but don't know about is only an obstacle on our way to being a "Charles Darwin" but also has two other implications:
- 1. Unreasonable budget spent
- 2. An environmental impact (see our corresponding article).
Too many data sources. Data can be generated by the lab tools/software, processed and transformed by software, provided, and stored in several data storage systems across the same organization. Such scattered provisioning does not allow researchers to collect required data to extract value from the batch of data needed.
Too many knowledge sources. Without a unified description policy and data indexing, it is impossible to effectively identify the data and generate insights even if all the files are gathered in one place. This is also one of the main reasons why data scientists spend most of their time on data cleaning and harmonization.
Scientific data has a peculiar structure. Generic data catalogs were invented to identify files using basic search criteria (file name, location, date created, owner, etc.). Initially designed for finance verticals, they cannot handle the complex phenotypic data required for Life Sciences experimental data analytics. Many companies utilize generic catalogs alongside manual curation and internal tools that try to integrate data from all the sources that it is siloеd in. In another article, we dive deeply into why a standard file-based paradigm does not efficiently work with scientific data [link to the article].
Some experimental data is heavy, so it is inefficient to search across and interact with it in a traditional file-based manner (e.g., 10 GB per sample of imaging data).
Data management is the crucial and least attractive step of working with data. Organizing data is an activity considered dull, so people minimally do that trying to avoid it as much as possible. Because of that, data scientists still spend 60-80% of their time cleaning data. It is estimated that 50% of experiments could be eliminated by better use and management of the data we already have.
The hurdles above are present everywhere. Being not efficient with the ever-growing volume of data is not a bad thing. It indicated that the technologies of data generation (and the number of data sources) are evolving, and your organization is adopting these changes to perform better. But with it comes the reckoning. Step by step, we become overwhelmed, swamped, and eventually drowned in the data ocean. Sooner or later, it only depends on your organization's resources.

FAIR data transformation
Genestack has designed a Six-Steps Data Operation Workflow to channel this constant data flood for FAIR data transformation.
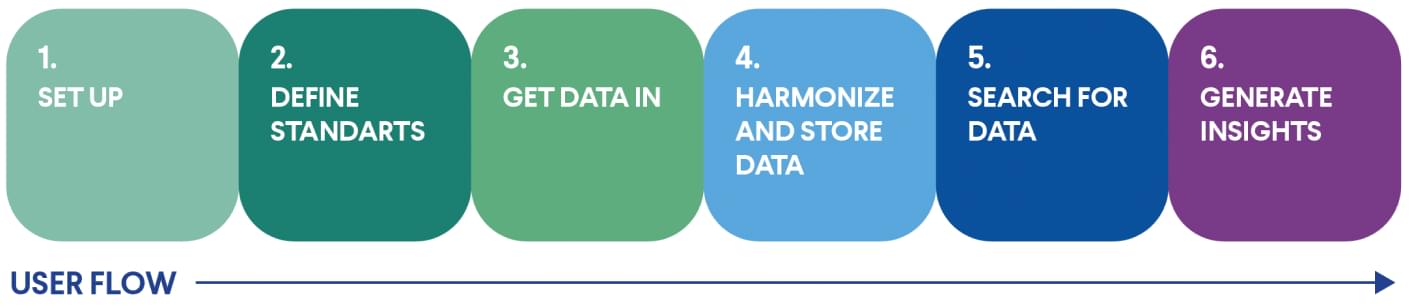
- 1. Data Framework Set-Up. Prepare the system to be used for a particular organization. Includes technology, storage, departments, users, and permissions.
- 2. Define Standards. Design data models, curation guidelines, attributes, vocabularies, and access permissions.
- 3. Get data in. Connect the system with other 3rd party data generation and storage systems. Upload, parse and store the data according to the defined data model.
- 4.Harmonize and store the data. Apply standards defined in the second step to the corresponding data.
- 5. Search. Make data findable.
- 6. Generate Insights. Prepare identified data chunks for further analysis and interpretation either within the system or via exporting it to be analyzed in another application.
Step 6 is the ultimate goal for any data-related project. However, steps preceding it are inevitable for generating the correct results. Genestack's goal is to reduce users' time dealing with data ingestion and harmonization so they can eventually focus on data analysis and interpretation.
The following articles will dive deeply into each step and overview different options applicable to various organizations.
Genestack accelerates the speed to breakthrough in Life Sciences by unlocking the power of data. Our Data curation, management and search platform help your teams be more effective, efficient and impactful in their research by reducing redundancy in experiments and increasing the usability of your existing legacy and public data.
Learn more at www.genestack.coma> or contact sales@genestack.com