There is a global push towards novel technologies and IT systems in the pharmaceutical industry, driven by the need to improve the drug discovery process. Genestack is very proud to be participating at the 16th Annual Pharmaceutical IT Congress in London, on 20-21st September, to support this push.
Genestack has long been recognised as experts in pharmaceutical IT systems. Using our unique modular approach to data architecture we help our customers take control of their infrastructure, improve data integration and support better data and metadata management.
This is not the only way we support better utilisation of Life Science Data. On top of our modular approach to data architecture, we also develop specialised apps to support key steps in the Life Science Data workflow. We are excited to launch our first public specialised app, Expression Data Miner at this game-changing event.
BOOK A MEETING WITH OUR TEAM
There are many ways to get involved
Is Your Architecture AI Ready?
Life Science Data expert and CEO of Genestack Dr Misha Kapushesky will be discussing current polls on the implementation of A.I. and machine learning techniques within Pharma and discusses what is holding back organisations from making the most of their A.I. initiatives.
PLUS we drop the curtain and release our first specialised app Expression Data Miner live at this event, with a sneak preview at the end of this thought-provoking talk.
Thursday 20th September | Pharmaceutical IT Track | 12:20
Be the first to see Expression Data Miner in action
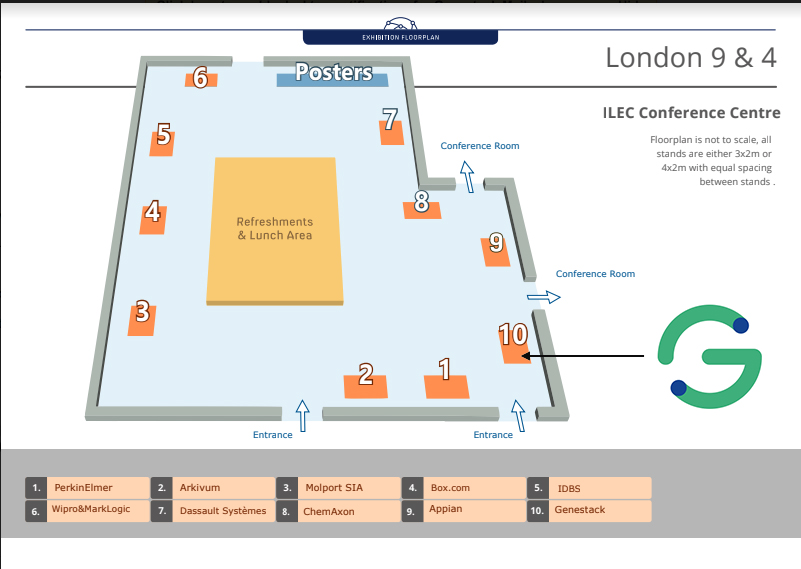
Our CEO Dr Misha Kapushesky and VP of Sales & Marketing Imad Yassin will be available to meet with you throughout the Pharmaceutical IT Congress. To find out more about Genestack and our latest app Expression Data Miner or to arrange a meeting with the team, visit our stand at booth 15.
BOOK A MEETING WITH OUR TEAM
Expression Data Miner is a new tool enabling biologists to interrogate and visualise expression data, at scale, without the support of a bioinformatician.
By enabling biologists to mine private and public transcriptomic datasets, scaling to hundreds of thousands to millions of samples on the fly, it accelerates and automates one of the key steps in the production of a comprehensive target report for drug discovery R&D management.
Find out more

BOOK A MEETING WITH OUR TEAM