

ODM is the single source of truth for your biological research data — ingesting, cataloguing, curating, and making data queryable across studies, data types, and scientific domains. FAIR-compliant by design. AI-ready by default.

A collaborative data ecosystem
We have specific APIs and GUI for different user classes, such as data managers, bioinformaticians and discovery scientists, so that everybody can harness the power of Life Science Data in their day to day work.”
ODM IN NUMBERS
100M+
single-cell transcriptomes queried in seconds from HCA, GEO, and Biobanks19M
indexed variants queried per minutePBEBscale
designed for the largest research data environmentsVisibility across every study, sample, data file, and metadata record your organisation has ever generated. From the latest experiment to years of legacy data, across all data types. Empowering every scientific stakeholder to explore and use it with confidence
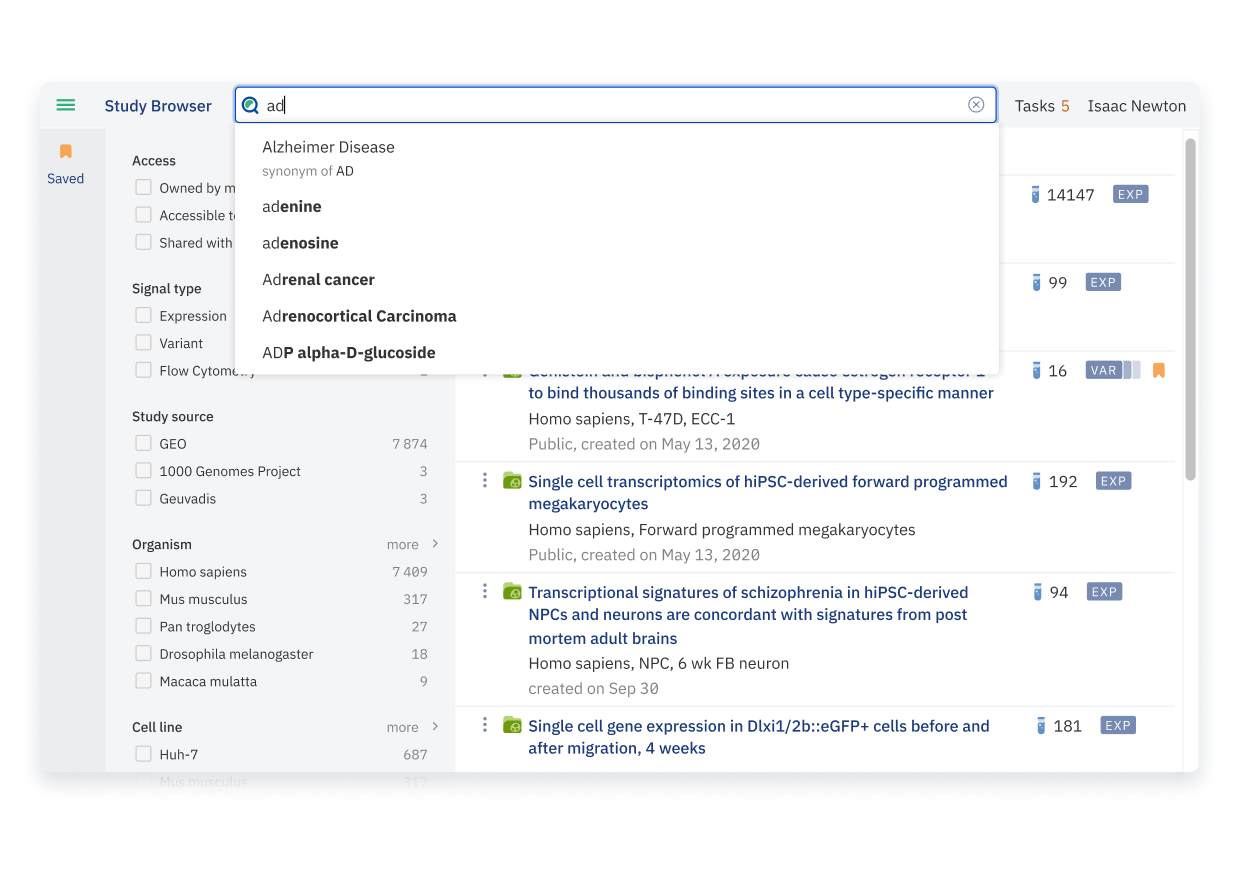
Validate and harmonize your metadata across studies, ensure it’s complete and conforms to your data model, and power AI / ML.
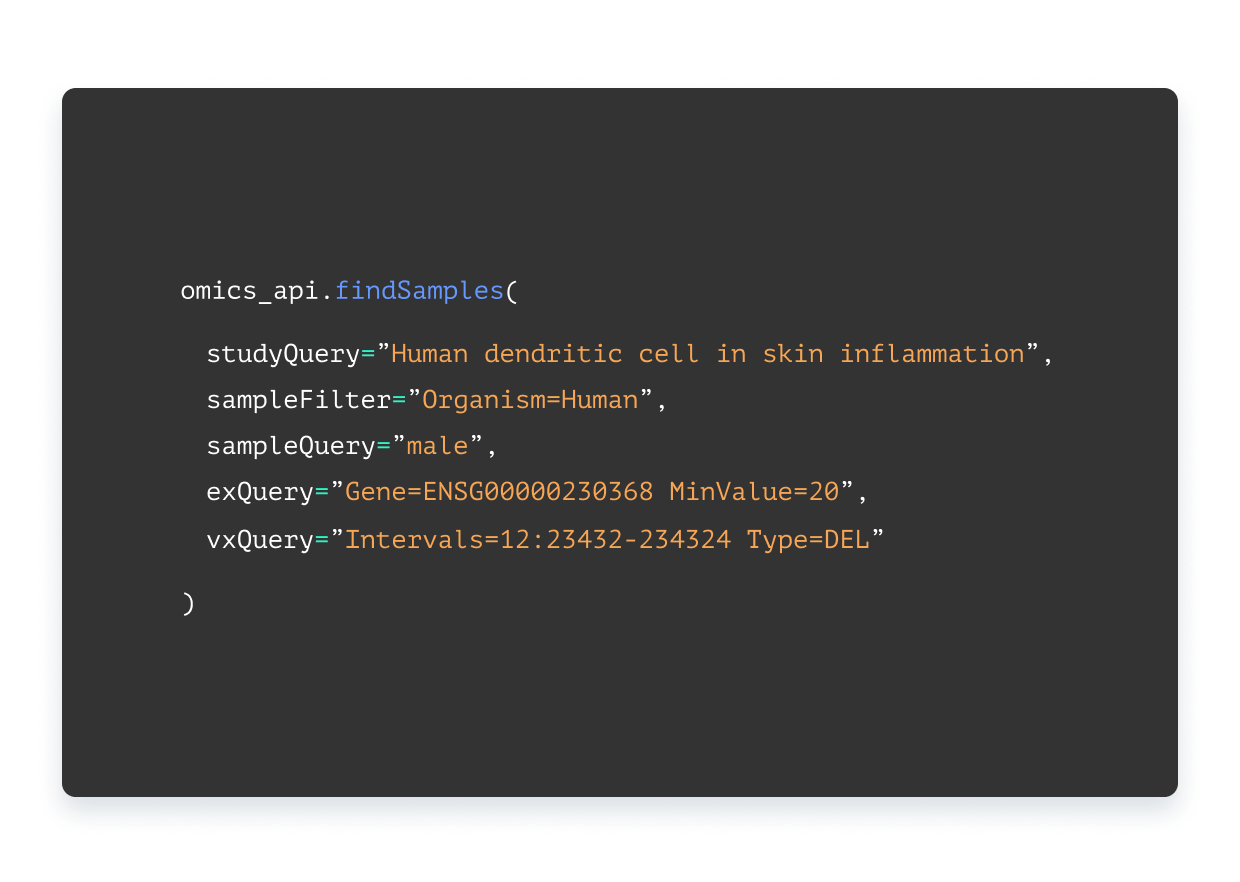
Across metadata and data simultaneously — via well-documented RESTful APIs. From sample descriptors to gene expression values and genomic variants.





Ingest data from upstream systems and public sources into a single governed foundation for research data.
Harmonise studies, samples, files, and metadata across omics with curation workflows and controlled vocabularies.
Query harmonised metadata and data across studies, omics, and domains for downstream analytics and AI workflows.
Seamless fit with existing IT landscapes












ODM supports a broad range of data types: genomics, transcriptomics, proteomics, spatial and suspension single-cell data, imaging (including radiomics and histopathology), flow cytometry, wearables, electrophysiology, real world data from biobanks and EHR systems, and time series/manufacturing data. It is designed to be data-type agnostic and extensible.
“Omics” is the shorthand for many system-wide investigations in biology. Genomics is the study of genomic information, for example genetic variation at specific locations in the genome between individuals. Transcriptomics is the study of which genes are transcribed/expressed and at what level. Proteomics aims to identify and/or quantify the proteins that are present in a sample. By “multi-omics”, we refer to the capability of making cross-study, cross-omics queries across all your data in ODM, e.g. find studies with human samples from adult females over 30 years of age which have HER2 gene expression and have mutation detected at amino acid position 438 in the BRCA1 gene”. Such queries are possible because ODM indexes not only metadata (e.g. sample information) but also data (e.g. the expression level of a particular gene in each sample of a study). ODM supports both metadata-level queries (sample descriptors, study context) and data-level queries (e.g. specific gene expression values or genomic variants) — simultaneously, at scale.
Get in touch to request a demo via our website. A member of our team will get back to you within two business days.
No. ELNs are designed to replace traditional pen-and-paper lab notebooks in capturing all the text and images associated with conducting an experiment. The focus is on the researcher’s point of view and how to reproduce a methodology. Records in ELNs often read like work logs, protocols or diaries without the confine of any data model or the use of controlled vocabulary. In contrast, ODM has a focus on the data that is produced as a result of an experiment and an experiment’s context (the metadata). It ensures both data and metadata are curated, programmatically searchable, reusable and ready for downstream integration across an organization.
Yes. ODM has built-in RESTful APIs which allow you to import (meta)data from ELNs or export (meta)data to ELNs.
Yes. ODM can integrate at several different stages in the data production workflow. Typically it is used as the single source of truth for Life Science Data after the data has been processed from an instrument, but it can also be used prior to data generation to design studies and collect information in a controlled fashion. RESTful APIs allow simple integration of both upstream and downstream processes.
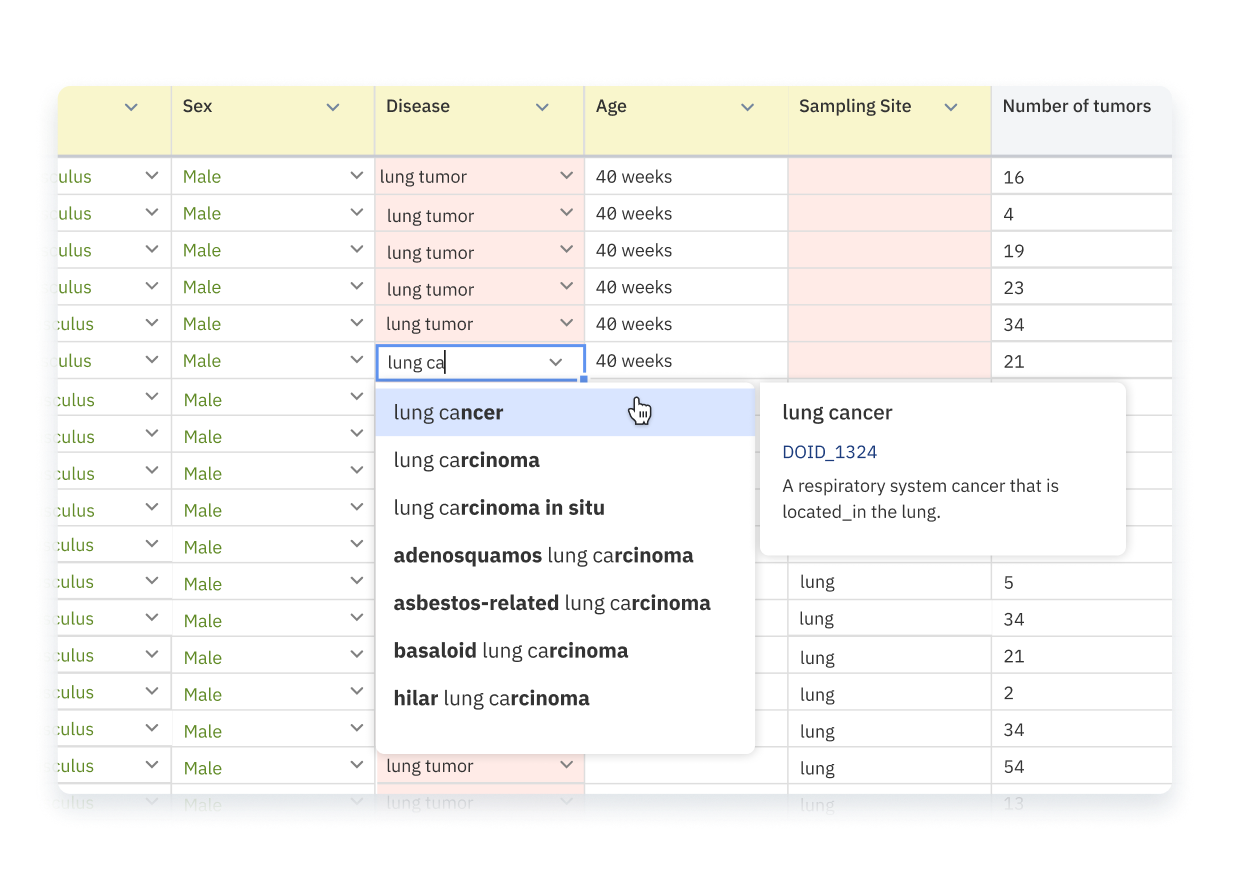
Yes. ODM makes it easy for curators to annotate metadata, which can optionally be standardized using controlled vocabularies and ontologies. Data managers or admins can set up ODM templates which specify the controlled vocabulary or ontology to use for a given metadata field, for example, “Use NCBI Taxonomy for the sample metadata field Organism”. In this case, during manual curation, NCBI Taxonomy terms will be suggested in a drop-down menu to the curator when filling in the value of Organism. Moreover, all metadata values will be validated on-the-fly against the designated controlled vocabularies or ontologies, including metadata that are programmatically imported to or curated in ODM.
Yes. We can either provide you with tools to do this or do it on your behalf. Plain comma-separated values (csv), obo and owl formats are supported. Out of the box, ODM is pre-loaded with the following ontologies/controlled vocabularies: NCBI Taxonomy for species, UBERON for mammalian tissues, Cell Ontology for cell types, Cellosaurus for cell lines, Disease Ontology for diseases, ChEBI for small molecules/compounds as well as common controlled vocabulary for measurement units and sex.
ODM’s APIs allow data querying and streaming for bioinformaticians or data scientists to build flexible, custom visualizations. We can help provide lightweight R-shiny and Jupyter Notebook examples, such as a simple application for gene expression look-up when a user enters a gene ID or gene symbol, or creating t-SNE plots from single-cell RNA-seq data for non-technical users. ODM also includes an LLM-powered Data Exploration Companion that generates AI-assisted visualisations and statistical analysis suggestions directly from conversational queries — with transparent referencing of underlying data.
Yes. Some examples of ODM’s bulk operation are bulk replace, GUI Excel-like drag/drop, auto fill-down, and rule-based replacements via a Python script.
Yes, it is easy to share your studies with different groups of ODM users. Depending on the role of a user, he/she can have different privileges in the sharing process and group management. At the most basic, ODM has non-sharing users who can only view the files shared with the group but cannot share them further. Sharing users, on the other hand, have rights to share data. Finally, within ODM your organization can have group administrators, who in addition to the rights of a sharing user, can invite or remove users and change their privileges.
It depends on which level you want to use ODM. There is an intuitive GUI which allows easy searching for studies of interest and data curation without programming knowledge, while the RESTful APIs are available for users with programming skills who wish to query (meta)data and to scale up operations.
ODM supports several user authentication mechanisms such as (i) login and password authentication, (ii) Single Sign-On (SSO) authentication using SAML, and (iii) OAuth 2.0 authentication. ODM has built-in admin, write, and read authorisation levels, with group-based controls for each. ODM’s built-in authorization model is granular and supports most use cases. It can be synced with external permission systems, e.g. Active Directory.
ODM supports a broad range of data types: genomics, transcriptomics, proteomics, spatial and suspension single-cell data, imaging (including radiomics and histopathology), flow cytometry, wearables, electrophysiology, real world data from biobanks and EHR systems, and time series/manufacturing data. It is designed to be data-type agnostic and extensible.
“Omics” is the shorthand for many system-wide investigations in biology. Genomics is the study of genomic information, for example genetic variation at specific locations in the genome between individuals. Transcriptomics is the study of which genes are transcribed/expressed and at what level. Proteomics aims to identify and/or quantify the proteins that are present in a sample. By “multi-omics”, we refer to the capability of making cross-study, cross-omics queries across all your data in ODM, e.g. find studies with human samples from adult females over 30 years of age which have HER2 gene expression and have mutation detected at amino acid position 438 in the BRCA1 gene”. Such queries are possible because ODM indexes not only metadata (e.g. sample information) but also data (e.g. the expression level of a particular gene in each sample of a study). ODM supports both metadata-level queries (sample descriptors, study context) and data-level queries (e.g. specific gene expression values or genomic variants) — simultaneously, at scale.
Get in touch to request a demo via our website. A member of our team will get back to you within two business days.
No. ELNs are designed to replace traditional pen-and-paper lab notebooks in capturing all the text and images associated with conducting an experiment. The focus is on the researcher’s point of view and how to reproduce a methodology. Records in ELNs often read like work logs, protocols or diaries without the confine of any data model or the use of controlled vocabulary. In contrast, ODM has a focus on the data that is produced as a result of an experiment and an experiment’s context (the metadata). It ensures both data and metadata are curated, programmatically searchable, reusable and ready for downstream integration across an organization.
Yes. ODM has built-in RESTful APIs which allow you to import (meta)data from ELNs or export (meta)data to ELNs.
Yes. ODM can integrate at several different stages in the data production workflow. Typically it is used as the single source of truth for Life Science Data after the data has been processed from an instrument, but it can also be used prior to data generation to design studies and collect information in a controlled fashion. RESTful APIs allow simple integration of both upstream and downstream processes.
ODM is not a data analysis software per se. However, you can export data programmatically via ODM’s API for analysis by third party/external analysis pipelines with great flexibility. In addition, ODM plays a key role in making your organization’s data analysis-ready by making it FAIR (findable, accessible, interoperable, reusable) and liquid i.e. readily consumable data by AI/ML tools without further wrangling.
ODM’s APIs allow data querying and streaming for bioinformaticians or data scientists to build flexible, custom visualizations. We can help provide lightweight R-shiny and Jupyter Notebook examples, such as a simple application for gene expression look-up when a user enters a gene ID or gene symbol, or creating t-SNE plots from single-cell RNA-seq data for non-technical users. ODM also includes an LLM-powered Data Exploration Companion that generates AI-assisted visualisations and statistical analysis suggestions directly from conversational queries — with transparent referencing of underlying data.
Yes, it is easy to share your studies with different groups of ODM users. Depending on the role of a user, he/she can have different privileges in the sharing process and group management. At the most basic, ODM has non-sharing users who can only view the files shared with the group but cannot share them further. Sharing users, on the other hand, have rights to share data. Finally, within ODM your organization can have group administrators, who in addition to the rights of a sharing user, can invite or remove users and change their privileges.
It depends on which level you want to use ODM. There is an intuitive GUI which allows easy searching for studies of interest and data curation without programming knowledge, while the RESTful APIs are available for users with programming skills who wish to query (meta)data and to scale up operations.
Although recommended requirements depend on the amount of an organization’s data assets, the starting minimum hardware requirements are 8 CPU cores and 64GB RAM*, with no special network requirements. Deployment can be on the cloud (Saas and VPC) and/or on-prem.
ODM is available as SaaS, VPC (private cloud), or on-premise. Deployment is configured to fit your organisation's IT architecture, data governance requirements, and security policy.
Firstly, our team will assess your organization’s needs and goals, and give you a demo of ODM. Our scientists and developers will then work with you to map your use cases and to identify the best configuration/customization of ODM for your organization. This is followed by a Proof of Concept (PoC) project - fully supported with training workshops - where your teams will be able to try ODM hands-on, at the end of which we provide a report with a gap analysis, and recommendations on how to move forward for deployment and beyond. Finally, there will be a full deployment and scale-up, with maintenance and additional development provided on a services basis.
We have several years of experience consulting and providing solutions in the data management space for a wide customer base, including large organizations in the pharmaceutical, consumer goods, and agriscience sectors. Genestack ODM is the result of several years of close work with a top pharmaceutical company, and it is getting adopted by top firms in other industry sectors. By choosing ODM your organization will benefit from both our scientific and software development expertise, and our experience in the data management field. This brings your organization efficiency savings and expert advice on best practises in data management. In addition, Genestack ODM is modular and future-extensible, saving the cost of in-house softwares being too monolithic and hard to extend/maintain for new data types.
Get in touch to request a demo via our website. A member of our team will get back to you within two business days.
Yes. ODM has built-in RESTful APIs which allow you to import (meta)data from ELNs or export (meta)data to ELNs.
Yes. ODM can integrate at several different stages in the data production workflow. Typically it is used as the single source of truth for Life Science Data after the data has been processed from an instrument, but it can also be used prior to data generation to design studies and collect information in a controlled fashion. RESTful APIs allow simple integration of both upstream and downstream processes.
Yes, it is easy to share your studies with different groups of ODM users. Depending on the role of a user, he/she can have different privileges in the sharing process and group management. At the most basic, ODM has non-sharing users who can only view the files shared with the group but cannot share them further. Sharing users, on the other hand, have rights to share data. Finally, within ODM your organization can have group administrators, who in addition to the rights of a sharing user, can invite or remove users and change their privileges.
We take security very seriously and are ISO 27001 compliant.
ISO 27001 is one of the most widely recognized and internationally accepted information security standards. It identifies requirements for a comprehensive Information Security Management System (ISMS), and defines how organisations should manage and handle information in a secure manner, including appropriate security controls.
In order to achieve the certification, Genestack’s compliance was validated by an independent security firm after demonstrating an ongoing and systematic approach to managing and protecting company and customer data.
ODM supports several user authentication mechanisms such as (i) login and password authentication, (ii) Single Sign-On (SSO) authentication using SAML, and (iii) OAuth 2.0 authentication. ODM has built-in admin, write, and read authorisation levels, with group-based controls for each. ODM’s built-in authorization model is granular and supports most use cases. It can be synced with external permission systems, e.g. Active Directory.
Firstly, our team will assess your organization’s needs and goals, and give you a demo of ODM. Our scientists and developers will then work with you to map your use cases and to identify the best configuration/customization of ODM for your organization. This is followed by a Proof of Concept (PoC) project - fully supported with training workshops - where your teams will be able to try ODM hands-on, at the end of which we provide a report with a gap analysis, and recommendations on how to move forward for deployment and beyond. Finally, there will be a full deployment and scale-up, with maintenance and additional development provided on a services basis.
Genestack ODM is an enterprise software solution that allows organizations to catalog their data, ensure the metadata is accurate and conforms to a data model, and query their (meta)data via APIs for downstream integration with analysis pipelines and/or visualization tools. Through these functionalities Genestack ODM is expected to unleash the full potential of all the data collected by making it easy to find, access, interoperate and reuse - being aligned with FAIR principles. This is important because R&D and clinical trials in the life-science sector and beyond are increasingly becoming data-intensive: many pharmaceutical, agri-science, consumer goods, and healthcare organizations have accumulated a lot of heterogeneous, un-standardized legacy data scattered in disparate sources, with obscure permissions/access rights. ODM offers a scalable solution that ensures data liquidity — that data are readily consumable by popular data science or ML/AI tools without requiring further wrangling, speeding up data-driven business decision-making processes.
Unlike a data lake or warehouse, ODM is domain-aware — built specifically for life science data types, ontologies, and FAIR compliance. It enforces metadata standards, enables cross-study biological queries, and connects directly to analytical and AI workflows without requiring additional data engineering.
It’s becoming increasingly clear that not having systems and best practices for data management in place is a cost to organizations in many sectors, ranging from pharmaceutical, to agri-science, healthcare and consumer goods. Whilst it’s difficult to put a figure against these costs for individual organizations, a recent EU report estimates that not having FAIR research data is costing the European economy in excess of €26 bn/yr for time spent, cost of storage, licence costs, research retraction, double funding, impact on research quality, economic turnover, and machine readability of research data.
We have several years of experience consulting and providing solutions in the data management space for a wide customer base, including large organizations in the pharmaceutical, consumer goods, and agriscience sectors. Genestack ODM is the result of several years of close work with a top pharmaceutical company, and it is getting adopted by top firms in other industry sectors. By choosing ODM your organization will benefit from both our scientific and software development expertise, and our experience in the data management field. This brings your organization efficiency savings and expert advice on best practises in data management. In addition, Genestack ODM is modular and future-extensible, saving the cost of in-house softwares being too monolithic and hard to extend/maintain for new data types.
Get in touch to request a demo via our website. A member of our team will get back to you within two business days.
Yes. ODM can integrate at several different stages in the data production workflow. Typically it is used as the single source of truth for Life Science Data after the data has been processed from an instrument, but it can also be used prior to data generation to design studies and collect information in a controlled fashion. RESTful APIs allow simple integration of both upstream and downstream processes.
Perhaps, but in a good way. ODM allows your organisation to build a FAIR compliant eco-system - it can be at the centre of your FAIRification efforts, or it can plug-in to your existing workflows. While the amount of change ultimately is up to each individual organisation some cultural and strategic changes are generally advised in the context of any R&D digital transformation efforts. For example:.
(1) data must be seen as a common asset of the organisation and expected to be reused, instead of belonging to individual research groups for one-off investigations and analysis;
(2) the organisation will need to have a data management strategy if it doesn't have one already;
(3) the data model needs to be agreed and adhered to by all users;
(4) dedicated administrators or data managers should be appointed or hired to enforce organisation-wide data policy and to safeguard data integrity.
We take security very seriously and are ISO 27001 compliant.
ISO 27001 is one of the most widely recognized and internationally accepted information security standards. It identifies requirements for a comprehensive Information Security Management System (ISMS), and defines how organisations should manage and handle information in a secure manner, including appropriate security controls.
In order to achieve the certification, Genestack’s compliance was validated by an independent security firm after demonstrating an ongoing and systematic approach to managing and protecting company and customer data.
Genestack develops its Genestack ODM product through establishing requirements that have been cross-referenced and aligned to 21CFR Part 11, ICH Guideline for good clinical practice E6 (R2) and ISO 27002 information security controls.
These requirements are a primary input to the design and development of Genestack ODM and enable our clients to comply with the applicable regulatory requirements during the use of the product.
Genestack ODM is GCP compliant.
Contact Genestack
To discuss your projects, challenges or to ask us any questions